打破全球语言壁垒:Meta 推出支持 1600 种语言的语音识别系统并开源
Meta的基础人工智能研究团队推出了“全语种自动语音识别系统”(Omnilingual ASR),支持超过1600种语言的语音转写,大大扩展了现有语音识别技术的语言覆盖范围。此前,多数语音识别工具主要关注几百种资源丰富的语言,而全球现存的7000多种语言中,大多数由于缺乏训练数据而难以获得人工智能支持。Omnilingual ASR旨在缩小这一差距。

在Omnilingual ASR支持的1600种语言中,有500种是首次被任何AI系统所覆盖。该系统被视为迈向“通用语音转写系统”的重要一步,有望打破全球语言障碍,促进跨语言沟通与信息获取。根据Meta公布的数据,对于测试中的1600种语言,Omnilingual ASR对其中78%的语言实现了低于10%的字符错误率;对于至少拥有10小时训练音频的语言,达到此精度标准的比例上升至95%;即使对于音频时长不足10小时的低资源语言,也有36%达到了低于10% CER的表现。
为了推动后续研究和实际应用,Meta还发布了“全语种ASR语料库”,这是一个包含350种代表性不足语言的大规模转录语音数据集。该语料库采用知识共享署名许可协议开放获取,旨在支持开发者与研究人员针对特定本地语言需求构建或适配定制化的语音识别模型。
Omnilingual ASR的关键创新之一是其“自带语言”功能,该功能基于上下文学习机制实现。用户只需提供少量配对的语音与文本样本,系统即可直接从中学习,无需重新训练或依赖高算力资源就能添加新语言。理论上,这种方法可将Omnilingual ASR的支持能力扩展到5400多种语言,远超当前行业标准。尽管对于极低资源语言的识别质量尚不及完全训练的水平,但这项技术为许多之前完全缺乏语音识别能力的语言社区提供了可行方案。
Meta以Apache 2.0开源许可协议发布了Omnilingual ASR的所有模型,允许研究人员与开发者自由使用、修改及商用;配套数据集则采用CC-BY协议开放。Omnilingual ASR模型系列包括适用于低功耗设备的轻量级3亿参数版本以及追求顶尖精度的70亿参数版本,满足不同应用场景的需求。所有模型均基于FAIR自主研发的PyTorch框架fairseq2构建。
热点推送
-

打破全球语言壁垒:Meta 推出支持 1600 种语言的语音识别系统并开源
Meta的基础人工智能研究团队推出了“全语种自动语音识别系统”(Omnilingual ASR),支持超过1600种语言的语音转写,大大扩展了现有语音识别技术的语言覆盖范围
2025-12-05语音识别,Meta -
雅迪电动车:已推出 68 款符合新国标的车型,网传“铁皮座椅”等并非行业主流设计、主流产品
雅迪科技集团有限公司发布了关于积极落实电动自行车新国标的声明。中国自行车协会近期对电动自行车相关问题进行了回应和倡议,雅迪公司积极响应并坚决执行。 《电动自行车安全技术规范》新国标已于12月1日全面实施
2025-12-05雅迪电动车,新国标电动车 -
Keychron 推出 K2 HE 全木特别版机械键盘:三模连接,佳达隆双轨磁轴
Keychron推出了K2 HE全木特别版机械键盘,其主要特色是将普通版的铝制外壳替换为胡桃木材质。这款键盘售价199.99美元,约合人民币1414元
2025-12-05Keychron,佳达隆双轨磁轴 -
出师未捷:奥尔特曼上诉失败,OpenAI 首款 AI 硬件恐因侵权被迫改名
科技媒体9to5Mac报道,OpenAI与前苹果设计总监Jony Ive的硬件合作项目在品牌命名上遇到法律障碍。美国第九巡回上诉法院本周三维持了此前下达的临时限制令,禁止OpenAI在其营销中使用“io”这一品牌名称
2025-12-05奥尔特曼,OpenAI,AI -
三星展示 40Gbps GDDR7 显存:3GB(24Gb)容量,12 纳米 DRAM 制程工艺
三星在首尔举行的2025年度韩国科技节上展示了40Gbps GDDR7显存,容量为3GB(24Gb)。这款显存获得了“总统级表彰”,采用三星12nm DRAM工艺制造,相当于10nm级别
2025-12-05三星 -
华为李小龙:Mate 80 RS 手机不只支持显示 BT.2020 色域,高饱和场景拍照也可自动切换
华为终端BG CTO李小龙在微博上透露,华为Mate 80 RS非凡大师手机拥有一项全系独占功能
2025-12-05华为,Mate,80 -
realme 真我 P4x 5G 手机发布:天玑 7400 Ultra 芯片,1080P 144Hz LCD 高刷屏
realme真我已在印度市场推出P4x 5G手机,这款手机定位中低端,搭载联发科天玑7400 Ultra芯片,并配备7000mAh大电池
2025-12-05天玑,7400,Ultra -
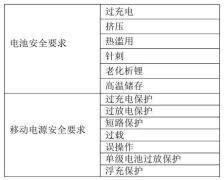
充电宝要标“建议安全使用年限”,工信部《移动电源安全技术规范》公开征求意见
工信部发布公告,公开征求对《移动电源安全技术规范》和《电子电器用锂离子电池和电池组安全 第 4 部分:玩具》两项强制性国家标准(征求意见稿)的意见。公示时间为2025年11月12日至2025年12月11日
2025-12-05充电宝,移动电源,工信部 -
11 月 13 日见,东风日产首款插混轿车 N6 预售定档
东风日产首款插混轿车N6将于11月13日开启预售,预估价格为12万-15万元,并将在本季度正式上市
2025-12-05东风日产,东风日产N6 -
JPR:全球客户端 CPU 市场 2025Q3 同比增长 2.2%、环比下降 2.2%
机构Jon Peddie Research在10日发布报告称,2025年第三季度全球客户端CPU市场连续三个季度实现环比扩张,增幅为2.2%,但同比出现2.2%的下滑
2025-12-05处理器,CPU,JPR -
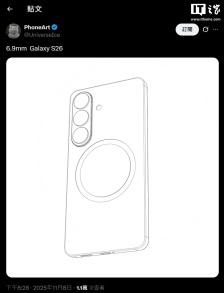
消息称三星 Galaxy S26 Ultra 手机支持 25W Qi 2.2 无线充电,充电速度提升 40%
据韩媒报道,三星计划为即将推出的Galaxy S26 Ultra手机配备25W无线充电功能,而S26标准版和S26+则将配备20W无线充电。相比原来的15W功率,25W无线充电可将充电时间缩短40%左右
2025-12-05无线充电,三星,Galaxy -
淘宝闪购 / 饿了么:将自愿执行《外卖平台服务管理基本要求》国家标准
市场监管总局发布了《外卖平台服务管理基本要求》推荐性国家标准,以应对近年来外卖行业存在的“幽灵外卖”等问题。淘宝闪购和饿了么对此发布声明,表示将自愿执行该标准,并将其融入平台运营管理和服务流程中
2025-12-05淘宝闪购,饿了么,外卖平台 -
ATK 推出 A9 Air 大师版鼠标:中大手全能模具,47±3g 超轻设计
ATK今日推出了A9 Air大师版鼠标,这款鼠标采用了准对称的中大手全能模具设计,配备300mAh电池,整体重量约为47g
2025-12-05鼠标,ATK -
潘通 Pantone 2026 年度代表色“云上舞白”公布,摩托罗拉限定机型曝光
潘通今日公布了2026年度代表色——PANTONE 11-4201 Cloud Dancer 云上舞白。这种颜色质感轻盈空灵,在喧嚣的世界中带来宁静与平和
2025-12-05潘通,彩通,Pantone -
哈佛民调:59% 美国年轻人认为 AI 会威胁自身就业前景
一项由美国哈佛大学青年民调发起的最新调查显示,大量美国年轻人对人工智能可能影响未来就业前景感到担忧。在18至29岁的受访者中,59%的人认为AI会冲击自己的就业前景,其中26%认为威胁严重,33%认为威胁较小,而23%的人完全不担心
2025-12-05人工智能,AI就业 -
爱玛电动车回应新国标车型质疑:网传产品仅为个别企业的车型,并非行业主流设计、主流产品
《电动自行车安全技术规范》新国标已于12月1日全面实施。近期网上出现了一些关于新国标车型的质疑,如“不能带小孩”“铁皮座椅”“超速刹车”等
2025-12-05爱玛电动车,新国标电动自行车 -
中兴推出 199 元轻量化 5G RedCap 随身 Wi-Fi U25S:支持内外置网卡 + 双频网络,3050mAh 大电池
中兴昨日上架了一款5G随身WiFi新品,型号为U25S,首发价199元。这款设备支持RedCap技术、双频Wi-Fi 6,并配备3050mAh电池和圆屏数显
2025-12-05中兴,5G,随身 -
Opera 更新 Neon 浏览器:引入 1 分钟深度研究、支持 AI 操作文档、集成 Gemini 3 Pro
Opera更新了其AI浏览器Neon,推出了“1分钟深度研究”模式
2025-12-04Opera,浏览器,AI -
限时优惠价 8.99 万元起,第三代吉利豪越 L 上市
新款吉利豪越 L 已上市,共推出 4 款车型,官方指导价为 9.99 万至 12.99 万元,限时优惠价 8.99 万至 11.99 万元。作为年度改款车型,新款豪越 L 依旧定位于中型 SUV 市场
2025-12-04吉利,豪越L -
“小钢炮”Abarth 电动化后市场表现糟糕,Stellantis 证实将重新打造燃油版
Stellantis 集团旗下的运动品牌 Abarth 正考虑重返燃油动力市场,可能以全新的菲亚特 500 Hybrid 为基础开发一款高性能小钢炮。品牌欧洲负责人 Gaetano Thorel 在接受采访时透露,这项计划正在认真评估中
2025-12-04菲亚特,菲亚特500 -
IT之家采访高通产品市场高级总监马晓民,解答大核 L2 缓存缩减疑惑
11月26日,高通发布了第五代骁龙8移动平台,旨在为价格较低的设备提供旗舰级体验。受邀前往发布现场,并与高通产品市场高级总监马晓民就产品定位、核心配置和技术趋势等关键问题进行了交流
2025-12-04高通,马晓民,骁龙 -
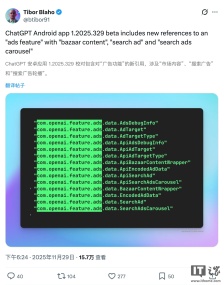
最新测试版 App 代码显示,ChatGPT 未来或引入广告
据报道,OpenAI 已经开始在内部测试为 ChatGPT 加入广告功能。如果这一功能正式上线,可能会彻底改变当前的网络商业模式
2025-12-04OpenAI,ChatGPT -
广东陆丰核电项目 1、2 号机常规岛建设全面启动,6 台机组建成年发电量约 520 亿千瓦时
中国电建承建的广东陆丰核电项目1、2号机常规岛建设已全面启动,这标志着我国规模最大的核电基地之一建设进入加速阶段。 陆丰核电基地位于广东省汕尾市陆丰市碣石镇田尾山,东临碣石湾,是粤东首个核电项目
2025-12-04中国电建,核电 -
荣耀 Magic5 系列手机获 MagicOS 10.0.0.116 升级:补齐通透图标、支持 iPhone 通知共享等
荣耀Magic5系列手机现已开启MagicOS 10.0.0.116版本升级,系统包大小约0.99GB。新版本带来了通透图标、通控中心实时模糊等特性,并新增支持荣耀手机与iPhone互相共享通知消息
2025-12-04iPhone,通知共享,荣耀 -
前 Facebook 安全主管 Alex Stamos 谈如何管理子女使用手机:信任,但要核查
前 Facebook 首席安全官 Alex Stamos 提出,管理子女的手机要遵循“信任,但要核查”的原则。当前许多中小学采取禁用手机、配发锁袋等措施,家长们也在纠结该给孩子多大程度的互联网自由
2025-12-04智能手机,未成年人,手机使用 -
起亚全新中大型纯电轿车预告图公布:弧形车身,车顶形似“泡泡”
起亚正准备推出一款全新纯电轿车,有望成为Stinger的精神继任者。从起亚发布的预告图来看,新车是一台轴距较长的四门轿车,采用前移式座舱设计,整体风格延续了起亚纯电家族的设计语言,线条比现有车型更加圆润,车顶呈明显的弧形泡泡状结构
2025-12-04起亚 -
美光宣布终止 Crucial 英睿达消费级业务,明年 3 月起停售相关内存与 SSD
对于PC游戏玩家、装机爱好者及硬件发烧友来说,美光科技宣布将终止其面向消费者的Crucial英睿达品牌业务的消息令人沮丧
2025-12-04Crucial,英睿达,美光科技 -
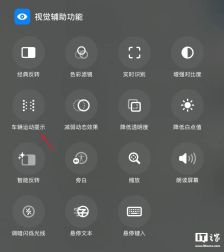
拯救晕车党:苹果 iOS 26“车辆运动提示”新增 6 种颜色与动态模式调节
苹果在iOS 26系统中升级了“车辆运动提示”功能,新增多项个性化设置,进一步解决晕动症问题。随着年龄增长,许多用户前庭系统对运动的敏感度发生变化,在乘坐网约车或移动车辆时阅读屏幕容易引发晕动症
2025-12-04苹果,iOS,26 -
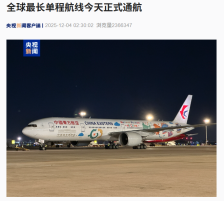
全球最长单程航线正式通航,中国至南美的航程缩短四小时以上
12月4日凌晨,中国东航MU745航班从上海浦东国际机场起飞,途经奥克兰最终抵达阿根廷布宜诺斯艾利斯。这条航线横跨东西半球与南北半球,航程约两万公里,刷新了全球最长单程航线的纪录,并将中国至南美的航程缩短四小时以上
2025-12-04中国东航,MU745,航班 -
卡梅隆:《阿凡达:火与烬》制作过程没使用任何 AI 技术
詹姆斯・卡梅隆希望全球观众在《阿凡达:火与烬》上映前明确知晓,这部续集的制作过程中未使用任何生成式人工智能技术
2025-12-04阿凡达火与烬,卡梅隆,AI