高德宣布 TrafficVLM 模型“重磅升级”:预知超视距路况,AI 带来“天眼”视角
9月19日傍晚,高德通过官方公众号宣布实现TrafficVLM(交通视觉语言模型),旨在帮助用户掌握全局交通状况,提升驾驶体验。
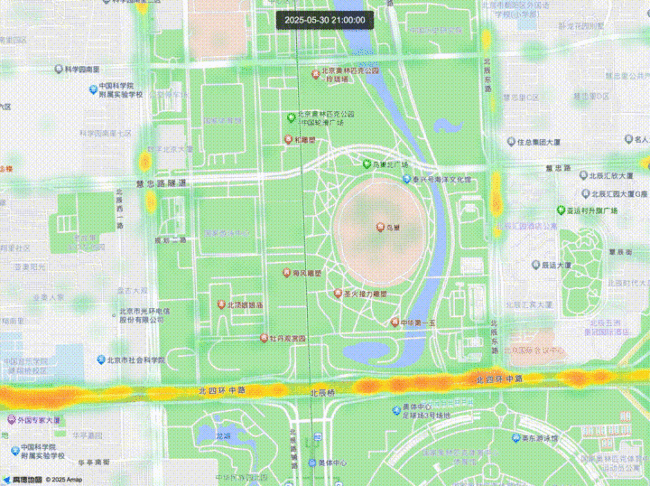
在现代交通环境中,驾驶者常面临信息盲区的问题。例如,在复杂的路口穿梭时只能看到眼前的车流,无法预知百米外哪个车道即将拥堵;在畅通的高速上行驶时,也难以预见前方因轻微刹车而引发的“幽灵堵车”。这些局部视角的限制使得驾驶者难以做出最优决策。因此,此次升级的TrafficVLM模型旨在解决这些问题。
全新升级的TrafficVLM依托空间智能架构,为用户提供“天眼”视角,使他们能够全面了解全局交通状况,在复杂环境中做出更优决策。该模型赋予每位驾驶者“全知视角”的能力,不再受限于局部视野,可以更直观地预知前方路况,从容应对潜在风险。
例如,当用户前方3公里的主干道上左侧车道因一起突发追尾事故形成新堵点时,TrafficVLM会通过实时孪生交通感知到这一异常,推理识别出事故点并洞悉其发展趋势:拥堵可能会快速蔓延,形成一个长达3公里的拥堵路段。高德会在用户到达拥堵点之前,及时推送通行建议:“前方三公里突发事故,大量车辆向右并线,推荐您提前靠右行驶,注意避让应急车辆。”
通过云端调度系统的快速响应,系统在拥堵发生时即刻下发观测指令,调取第一现场的视觉数据,并基于图像中的深度信息进行智能分析,精准还原拥堵点位的空间结构与交通态势。这意味着用户不仅能直观看到“前方堵车”,更能清楚理解为何需要变道、何时该减速,以及拥堵的真实成因与范围。这种从被动接收提示到主动洞察全局的转变,让用户摆脱了“盲人摸象”般的局限,实现对复杂路况的可视化、可感知、可预判的智慧导航体验。
该模型以视觉语言模型通义Qwen-VL为底座,基于高德海量、高度还原的交通视觉数据,完成了强化学习和数据训练。
热点推送
-

极摩客 EVO-T2 迷你主机亮相:最高可选英特尔酷睿 Ultra X9 388H 处理器,128GB LPDDR5X 内存
极摩客在CES 2026期间展示了EVO-T2迷你主机,基于英特尔Panther Lake平台打造,配备多样化接口,预计本季度上市
2026-01-07极摩客,CES,2026 -
摩根士丹利预警:苹果 iPhone 18 系列起售价有望不变,但大容量版本恐涨价
摩根士丹利最新发布的投资者报告显示,苹果在步入2026年之际面临严峻的硬件成本挑战。报告指出,自2025年末起,手机、个人电脑及服务器领域的上游供应日益紧张,导致原材料成本全面上扬
2026-01-07苹果,iPhone,18 -
亿万富翁投资人马克・库班:企业若想在未来竞争中存活,必须正确使用 AI
马克・库班认为,企业若想在未来竞争中存活,必须正确使用AI。他表示,未来只会存在两类公司,一类是真正善于使用AI的公司,另一类是其余所有公司。后者面临失败的风险,因为AI是一种足以改变商业格局的工具
2026-01-07马克·库班,人工智能 -
漫步者首款配 HDMI eARC 的紧凑型有源音箱:M90 亮相,解决多设备切换痛点
漫步者在CES 2026展会期间展示了以“现代家庭娱乐跨场景音频解决方案”为主题的全新音箱阵容。其中,一款名为M90的有源音箱成为焦点
2026-01-07漫步者,音箱,CES2026 -
小米 SU7 首次改款:全系标配激光雷达,预计 2026 年 4 月上市,新颜色“卡布里蓝”率先亮相
小米新一代SU7正式宣布,预计于2026年4月上市,并在今天上午10点开启小订。这款车型定位为豪华高性能纯电轿车,新颜色“卡布里蓝”率先登场。 雷军提到,2024年3月28日小米发布了SU7,4月份开始交付
2026-01-07小米,SU7,Ultra -
iPhone 18 落空:摩根士丹利预测 iPhone 21 系列才会上 2 亿像素传感器
摩根士丹利最新研报披露,苹果计划在2028年推出的iPhone 21中首次引入三星制造的2亿像素摄像头
2026-01-07iPhone,18,苹果 -
美国康奈尔大学、芝加哥大学研究:到 2050 年,健康类可穿戴设备或将产生百万吨电子垃圾
在CES 2026期间,拉斯维加斯展出了各种可穿戴健康设备,这些设备能够监测血糖、血压和运动状况。然而,据TechCrunch报道,这些新品背后隐藏的环境风险并未引起足够关注
2026-01-07CES,2026,智能手表 -
马斯克 xAI 宣布完成 200 亿美元 E 轮融资,原定目标 150 亿
马斯克旗下的AI初创公司xAI宣布完成了一轮200亿美元的E轮融资,超过了此前设定的150亿美元目标
2026-01-07xAI,Grok,马斯克 -
下一代奔驰 S 级将同时提供燃油、纯电车型,不再沿用现款 EQS 设计
奔驰正在为下一代S级规划一条“双线并行”的道路,未来的S级将同时提供燃油版和纯电版。这两种动力车型不会共用平台,而是从底层工程上彻底分开。 这一调整意味着奔驰正在修正此前以EQS为代表的纯电路线
2026-01-07奔驰,奔驰S级,EQS -
双万兆网口:蓝宝石推出 Mini-ITX 工业级主板,搭载 AMD 锐龙处理器 + Versal FPGA 加速器
蓝宝石在CES 2026上展示了其最新的Mini-ITX主板,这款主板搭载了AMD锐龙AI Embedded P132 APU及AMD Versal AI Edge Series Gen 2 FPGA加速器
2026-01-07蓝宝石,AMD,Versal -
小米公布团队接触相关 KOL 事件正式调查结果:辞退涉事人员,许斐、徐洁云遭通报批评并取消年度绩效奖金
小米公司发言人于1月6日晚在微博上表示,针对此前团队与相关KOL接触一事,公司立即启动了专项调查,并公布了初步结论。公关部总经理徐洁云宣布,相关接触已立即终止,并承诺未来不会合作
2026-01-07小米,徐洁云,许斐 -
Aqara 绿米推出 U400 智能锁:自带 UWB 超宽带,可实现无感解锁
Aqara绿米在CES 2026期间推出了U400智能门锁,这款门锁自带UWB超宽带技术,可实现免按指纹、看镜头或输密码的无感解锁体验。这款门锁的最大亮点是加入了UWB芯片,为智能手机或智能手表用户提供真正的免接触身份验证体验
2026-01-07Aqara,绿米,UWB -
骨伽发布 CES 2026 电源新品:白金 Polar V2、PV,金牌 GQ
游戏硬件品牌骨伽在CES 2026上推出了三款ATX 3.1电源新品,分别是白金效率的Polar V2和PV系列以及金牌效率的GQ系列。 Polar V2采用150mm长度外形规格,配备130mm FDB风扇和点阵美学格栅
2026-01-07骨伽,电源,CES2026 -
2025 年华为乾崑合作品牌再创佳绩,总销量超 90 万台
华为乾崑智能汽车解决方案宣布,到2025年其合作品牌的总销量将超过90万台。在2025年11月20日的华为乾崑生态大会上,华为智能汽车解决方案BU CEO靳玉志透露,华为乾崑智驾ADS合作车型的月销量突破了10万大关,创下历史新高
2026-01-07华为乾崑,靳玉志,智能汽车 -
苹果创始人乔布斯的遗物被拍卖:Apple I 原型机 5 万美元起拍,高中领结等私人物品现身
拍卖平台RR Auction举办了一场线上拍卖会,拍品包括苹果公司诞生车库使用过的办公桌、乔布斯高中时期戴过的领结等物品。部分产品起拍价低至100美元
2026-01-07RR,Auction,Apple -
海信发布全新一代 RGB-Mini LED 技术,首创玲珑 4 芯真彩背光
在CES 2026前夕,海信举办了一场展前发布会,正式发布了全新一代RGB-Mini LED技术,并推出了全球首款搭载该技术的超旗舰电视海信UX
2026-01-06海信,RGBMini,LED -
华硕 ROG CES 2026 联名小岛工作室推出 ROG Flow Z13-KJP 二合一笔记本,融入《死亡搁浅》游戏美学风格
华硕在CES 2026上发布了ROG Flow Z13-KJP笔记本,这是与小岛工作室合作的特别款产品
2026-01-06华硕,小岛工作室,CES -
摩托罗拉 Signature 手机渲染图曝光:骁龙 8 Gen 5 芯片
Evan Blass 在 X 平台上分享了摩托罗拉旗下 moto Signature 旗舰手机的系列图片
2026-01-06摩托罗拉,CES2026 -
无人快递车等发生交通事故后谁担责?从业人员称尚无统一标准,专家给出建议
随着无人驾驶技术的发展,外形方方正正的功能性无人车开始进入人们的生活
2026-01-06无人车,快递车,交通事故 -
LG 显示 Tandem WOLED 发布:基于 Primary RGB Tandem 2.0,峰值亮度达 4500 尼特
在经过一系列预热之后,LG Display 在 CES 2026 上正式推出了其最新一代 OLED 显示技术——Primary RGB Tandem 2.0,以及对应品牌 Tandem WOLED
2026-01-06LGD,LG,Display -
IT之家开箱小米 REDMI Note 15 Pro「车厘子红」:深邃浓郁高级红,开启 2026 红运当头
新年伊始,REDMI Note 15 Pro 系列新春版于1月1日上午10点正式迎来首销。为契合新春佳节的喜庆氛围,该系列特别推出了限定配色
2026-01-06红米,REDMI,Note -
OpenAI:全球每天有超过 4000 万人使用 ChatGPT 获取健康信息
根据人工智能公司OpenAI的一份报告,全球每天有超过4000万人使用ChatGPT来获取健康信息。美国医疗体系复杂且信息不透明,越来越多美国人正依赖人工智能工具应对这一挑战
2026-01-06ChatGPT,OpenAI -
剑指 Waymo:英伟达 L4 级自动驾驶出租车最早 2027 年上路
在CES 2026主题演讲中,英伟达首席执行官黄仁勋宣布,公司首款全栈自动驾驶汽车将于2026年第一季度在美国上路测试。他认为这将是机器人产业发展史上规模最大的领域之一
2026-01-06英伟达,AI,自动驾驶 -
黄仁勋官宣英伟达已投产 Vera Rubin:训练 AI 速度是 Blackwell 架构 3.5 倍、推理速度是其 5 倍
在CES 2026的主题演讲中,英伟达首席执行官黄仁勋介绍了新一代“Rubin”计算架构,并称其为当前AI硬件领域的最先进技术。该架构已进入全面量产阶段
2026-01-06黄仁勋,英伟达,CES2026 -
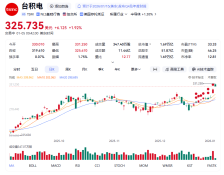
台积电股价再创历史新高,总市值达 1.7 万亿美元
今日美股开盘,台积电股价一度大涨3.4%,达到每股331美元,总市值接近1.7万亿美元。随后股价有所回落,降至约326美元
2026-01-06台积电 -
OPPO 在印度发布 A6 Pro 5G 手机:6.75 英寸 720P 120Hz LCD 屏幕,天玑 6300 芯片
OPPO在印度市场推出了A6 Pro 5G手机,这款手机的硬件配置与中国内地市场的A6 Pro有所不同。该机配备了一块6.75英寸720P分辨率的120Hz LCD屏幕
2026-01-06OPPO,A6,Pro -
消息称荣耀“Air”新机整机不到 165g,拥有某些友商 Pro 级影像能力
博主@数码闲聊站透露,荣耀即将推出一款名为“Air”的新机。这款手机整机重量不到165克,比iPhone Air更轻,并且在较小的机身内配备了旗舰级芯片、全能影像系统和全面的外围配置,电池容量也更大
2026-01-06荣耀,Magic8,Air -
铠侠推出 BG7 系列固态硬盘:面向 PC OEM 市场,可选 2230/2242/2280 长度
铠侠今天推出了BG7系列固态硬盘,该产品采用了第八代BiCS FLASH 3D闪存技术和CBA技术,主要面向PC OEM市场,适用于商用和消费级笔记本及台式整机
2026-01-06铠侠,BG7,系列 -
10 万亿 tokens!英伟达贡献全球最大规模开源数据集,并推四大开源 AI 模型
在CES 2026主题演讲中,英伟达首席执行官黄仁勋宣布大规模扩展其开源模型库,发布涵盖语言、机器人、自动驾驶及医疗四大领域的全新模型与数据集,进一步加速全行业的AI创新
2026-01-06英伟达,AI,CES2026 -
黄仁勋宣布首次为奔驰 CLA 引入英伟达 AI 端到端驾驶辅助软件 DRIVE AV,新车预计年底前上市
英伟达CEO黄仁勋在CES 2026上宣布,NVIDIA DRIVE AV驾驶辅助软件将首次搭载于全新梅赛德斯-奔驰CLA车型,并预计在今年年底前在美国推出
2026-01-06黄仁勋,NVIDIA,DRIVE