Stable Audio 2.5 企业级音频生成 AI 模型发布,号称“3 分钟曲目 2 秒钟完成”
Stability AI 正式发布了企业级音频生成模型 Stable Audio 2.5,该版本在音频细节和生成速度方面进行了提升,宣称仅需 2 秒钟即可创建 3 分钟的音频曲目。新模型的核心改进集中在音乐生成能力上,声称生成结果更加贴合实际编曲逻辑,能够呈现前奏、发展与结尾等完整多段式结构。此外,新模型对提示词的理解更为准确,在情绪描述和音乐风格词汇的把握上响应更符合预期。

新版模型还显著提升了音频生成速度,这主要得益于研发团队提出的后训练方法 ARC(Adversarial Relativistic-Contrastive)。这一技术通过结合相对式对抗训练与对比判别器,加速了扩散模型的生成过程,在保证音轨质量的同时显著降低了 GPU 推理耗时,实现了 2 秒钟生成长达 3 分钟的音频内容。
Stable Audio 2.5 还新增了音频修补功能,用户可以导入自己的音频文件并指定“延展位置”,模型会根据音频前后内容及整体曲风,将音频一键延长,特别适合剪辑等场景。
目前,Stable Audio 2.5 已可通过 StableAudio 官网直接试用,并支持本地化部署。需要注意的是,用户上传的音频文件不得包含受版权保护的内容,StableAudio 网站将利用自带的内容识别系统进行检测,以确保不侵犯他人版权。
热点推送
-

雷神 MIX NUC 迷你主机配置上新:AMD 锐龙 AI 9 HX 370,售价 6999 元
雷神推出了全新一代MIX NUC迷你主机,搭载AMD锐龙AI 9 HX 370移动处理器,提供32GB DDR5内存和1TB SSD存储,新品到手价为6999元,国补后价格为5599.2元
2025-11-13雷神,MIX,NUC -
小米之家重返法国巴黎,首家直营店即将开业
11月11日,小米法国副国家经理在微博上宣布,巴黎首家小米之家即将开业。这家新店将是直营门店。有网友询问之前在香榭丽舍大街是否已有店铺,对此,该经理回应称之前的店铺是由客户开设,因疫情原因暂时退出了市场
2025-11-13小米之家,巴黎 -
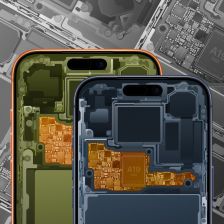
打磨近 3000 个图层:设计师推苹果 iPhone 17 Pro / Max 全新“透视”壁纸,9 种色调
设计师Basic Apple Guy耗时两个多月,为iPhone 17 Pro和iPhone 17 Pro Max创作了内部结构主题壁纸。这些壁纸之所以细节惊人,是因为其素材直接源于苹果官方的维修手册
2025-11-13iPhone,17,Pro -
法拉第未来宣布接入特斯拉超级充电网络,明年新车型配备 NACS 接口
法拉第未来 Faraday Future 宣布,自2026年起推出的新车型将配备NACS(北美充电标准)接口,并可直接接入特斯拉超级充电网络
2025-11-13法拉第未来,特斯拉充电,NACS -
奥迪全新概念赛车 R26 首秀,官宣明年进军 F1 赛事
明年新赛季揭幕时,奥迪将首次亮相F1赛场。为此,奥迪正式发布了全新的R26概念车,让外界提前一睹奥迪赛车的风采
2025-11-13奥迪,F1 -
美国法官推迟批准 Epic 与谷歌和解协议,需等待法律发生重大变化才能一锤定音
加州一名法官推迟批准Epic与谷歌之间的和解协议,这意味着两家公司关于内购抽成的纷争尚未结束。Epic在2020年起诉谷歌,指控其Android系统的Play商店构成事实性垄断,理由是超过95%的Android应用都通过Play商店分发
2025-11-13Epic,谷歌 -
自研 AI 芯片进展缓慢,微软 CEO 纳德拉计划借“OpenAI 之力”推进研发
北京时间今天清晨,据彭博社报道,微软计划借助对OpenAI定制AI芯片研发的访问权来推动自研芯片进展。微软CEO纳德拉在播客节目中表示,即使OpenAI在系统层面进行创新,微软也能全面获取这些成果
2025-11-13OpenAI,微软,纳德拉 -
苹果 iOS 26.2 Beta 2 更新汇总:UI 动画更 Q 弹、拓展液体玻璃设计
科技媒体9to5Mac发布了一篇关于苹果iOS 26.2 Beta 2更新内容的文章。此次更新主要为“测距仪”和“水平仪”等原生应用整合了液态玻璃设计语言,并调整了部分系统动画,使其更具弹性
2025-11-13iOS,26,苹果 -
Steam Machine 游戏主机正式亮相:Steam Deck 掌机 6 倍性能、支持光追,明年初开售
今天凌晨,Valve 正式发布了全新的硬件产品——“主机级”设备 Steam Machine。该设备将率先在目前销售 Steam Deck 的地区同步上市,计划于 2026 年初开售,具体价格与时间待后续公布
2025-11-13Steam,Steam,Machine -
华硕 ROG STRIX 吹雪 360 LCD 方屏版水冷上市,1529 元
华硕在10月末于电商平台上架了一款AIO水冷新品——ROG STRIX吹雪360 LCD方屏版,售价为1529元
2025-11-13华硕,水冷散热器 -
苹果 iOS/iPadOS 26.2 开发者预览版 Beta 2 发布
苹果今日向iPhone和iPad用户推送了iOS/iPadOS 26.2开发者预览版Beta 2更新,内部版本号为23C5033g。此次更新距离上次发布Beta/RC版本间隔8天
2025-11-13iOS,iPadOS -
涉案超 27 亿元!跨境赌博“十大逃犯”之一、“亚太新城”赌诈犯罪集团主犯佘智江成功引渡回国
近日,据媒体报道,我国公安机关通缉的跨境赌博“十大逃犯”之一、缅甸妙瓦底“亚太新城”赌诈犯罪集团主犯佘智江被成功从泰国引渡回国。这是中泰执法司法合作取得的重大成果,彰显了双方坚决打击网赌电诈犯罪的决心
2025-11-13电信诈骗,网络赌博,跨境赌博 -
智能手机厂商首家:小米应用商店打通腾讯元器智能体分发,无需额外开发或适配
小米应用商店宣布与腾讯官方智能体平台——腾讯元器完成能力打通,成为首家接入该平台的智能手机厂商。腾讯元器是一个零代码智能体创建与分发平台,提供低门槛的创建能力和优秀模型支持
2025-11-13小米应用商店,腾讯元器 -
奇瑞汽车就“天门山测试意外”致歉:防护绳脱落致车辆撞击护栏,将全力修复并承担赔偿责任
奇瑞汽车在11月13日凌晨发布了一份关于天门山挑战测试意外情况的致歉声明。声明中提到,2025年11月12日中午12时,风云X3L车型在湖南张家界天门山景区进行极限挑战测试时发生意外,导致测试中断,引起广泛关注
2025-11-13奇瑞汽车,风云,X3L -
小米米家 App 安卓端推送 11.1.505.302 体验版,3D 家居视图上线
小米近期为安卓用户推送了米家App的11.1.505.302体验版本,更新中引入了一系列新功能。其中包括“场景”页面和全屋动态看板,并对设计风格进行了调整
2025-11-12米家,App,小米米家 -
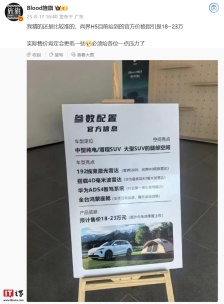
消息称鸿蒙智行尚界 H5 汽车官方价格指引 18~23 万元,实际可能更低
近日,博主@Blood旌旗分享了尚界H5的官方价格指引,该车定价在18至23万元之间。博主表示,实际售价可能会更低一些。 根据博主分享的图片,尚界H5定位为中型纯电/增程SUV,拥有大型SUV的腿部空间
2025-11-12尚界,H5,鸿蒙智行 -
人形机器人史上首个百米“飞人”诞生:具身天工 Ultra 夺得 100 米短跑项目冠军
2025世界人形机器人运动会正在国家速滑馆举行。在百米“飞人大战”决赛中,北京天工队的“具身天工 Ultra”机器人以21.50秒的成绩夺得全球首个人形机器人运动会100米短跑项目的冠军
2025-11-12北京人形机器人创新中心,世界人形机器人运动会,具身天工 -
曝苹果 iPhone 18 数字基础款推迟发布,下半年仅 Air、Pro / Max 及折叠屏四款高端旗舰
据韩国ETNews报道,苹果明年将不会发布“iPhone 18”基础款型号。今年苹果用Air/Slim替换了Plus型号,并计划在明年推出首款折叠屏iPhone,因此将对产品线进行扩展和调整
2025-11-12苹果,iPhone,18 -
史上首次:SK 海力士终结三星在 DRAM 行业长达 33 年的霸主地位
得益于AI带动的HBM需求以及与英伟达的独家供货合作,SK海力士在2025年上半年超越了保持33年霸主地位的三星电子,成为全球最大DRAM制造商
2025-11-12SK海力士,存储器 -
1080P 400Hz 内置电源,KTC 推出 24.1 英寸显示器“大师 25M1”
KTC已在京东上架了一款型号为“大师 25M1”的24.1英寸显示器,主打1080P 400Hz刷新率。这款显示器将于明天开始首销,商品页显示价格为4399元,但最终定价可能有所不同
2025-11-12KTC,显示器 -
苹果发布 Xcode 26.1.1:支持 Swift 6.2.1、与 ChatGPT 交互不再卡顿
苹果发布了Xcode 26.1.1版本更新,主要聚焦于修复一系列漏洞,并显著优化了其全“编码智能”AI编码辅助功能的性能。本次更新的核心是针对“编码智能”功能的性能和稳定性修复,同时增加支持Swift 6.2.1
2025-11-12Swift,Xcode,苹果 -
请 AI 当“减肥教练”并不可靠,斯坦福新研究警告称其会助长饮食失调
研究人员警告称,AI聊天机器人正在对饮食失调高风险人群造成严重威胁。最新报告显示,谷歌、OpenAI等公司的AI工具不仅提供节食建议,还传授如何掩饰病情的技巧,甚至生成鼓吹极端瘦身的内容
2025-11-12人工智能,AI减肥,AI医生 -
梅赛德斯-奔驰公布全新一代 GLB 内饰:七座、三联屏,星空顶吸睛
梅赛德斯-奔驰正加速更新旗下紧凑型车阵容,计划于12月8日推出第二代GLB。新车外观保持方正硬朗,内饰则彻底革新。奔驰公布了新车内饰的预告图,座舱布局与今年早些时候发布的CLA相似,采用三联屏设计,科技感更强
2025-11-12奔驰,glb -
索尼发布 PlayStation 显示器:27 英寸 120/240Hz 2K 屏,仅供日本及美国市场
索尼在State of Play发布会上公布了一款全新的27英寸游戏显示器,这款产品仅会登陆美国和日本市场。继推出PlayStation Portal远程播放器之后,索尼进一步拓展了硬件生态
2025-11-12索尼,playstation,显示器 -
海力士等三巨头齐聚 HBF 新赛道,“HBM 之父”预测英伟达将收购内存厂商
金正浩,韩国科学技术院电气工程学系教授,被誉为“HBM 之父”,近日在YouTube频道节目中表示,AI时代的权力正从GPU转向内存。他预测高带宽闪存(HBF)将成为继HBM之后的新战场,并认为英伟达未来可能收购一家内存公司
2025-11-12HBF,HBM,三星 -
不到三月 2499 → 1388 元腰斩:小米智能门锁 4 Pro 新低,隔空刷掌秒开锁
小米智能门锁4 Pro于8月末开售,支持AI掌静脉、3D人脸识别,原价2499元。目前京东PLUS会员可享受5.5折优惠,价格降至1377.68元
2025-11-12小米智能门锁,4,Pro -
朗科推出“企业级”3.5 英寸盘体移动机械硬盘,至高 28TB 容量
朗科Netac今日推出3.5英寸企业级移动硬盘K393。该设备基于企业级3.5英寸机械硬盘盘体,配备USB-C数据接口和DC-in独立供电接口。 K393移动机械硬盘提供12TB至28TB的容量选择,顺序读取速率为270MB/s
2025-11-12朗科,机械硬盘,移动硬盘 -
诈骗专家自己都差点被骗,新加坡反欺诈大会呼吁警惕二维码、AI 等新型骗术
9月4日,全球防网络诈骗的顶尖专家在新加坡举行会议。组织者通过一个模拟测试提醒大家注意网络安全:扫描二维码即可插队。结果显示,超过50人中了圈套。这一模拟骗局旨在提高与会者对二维码钓鱼攻击的认识,这类攻击会诱导受害者向恶意网站泄露个人信息
2025-11-12人工智能,反诈,防诈 -
苹果为 App Store 辩护:去年巴西开发者九成收入免佣金
苹果在巴西面临越来越大的监管压力,尤其是在App Store运营模式方面。近期,苹果引用了一项研究数据表明,2022年巴西地区的iOS应用创收达6380万雷亚尔,其中绝大部分收入无需支付佣金
2025-11-12App,Store,苹果 -
奔驰 CEO 康林松等欧洲汽车高管喊话欧盟:要学习中国经验
据英国《金融时报》报道,欧洲汽车行业多位高管建议欧盟效仿中国,在减排计划中纳入混合动力车。他们警告称,如果欧盟坚持2035年全面禁止燃油车,可能会对欧盟最大的产业造成风险
2025-11-12新能源汽车,纯电汽车,混动汽车