英伟达开源 Audio2Face 模型:AI 实时生成面部动画,多语言口型同步
9月25日,英伟达发布博文宣布开源生成式AI面部动画模型Audio2Face,包括模型、软件开发工具包(SDK)及完整训练框架。这一技术旨在加速游戏和3D应用中AI智能虚拟角色的开发。

该技术通过分析音频中的音素、语调等声学特征,实时驱动虚拟角色面部动作,生成精准的口型同步和自然的情感表情,适用于游戏、影视制作和客户服务等领域。Audio2Face支持两种运行模式:预录制音频的离线渲染和动态AI角色的实时流式处理。
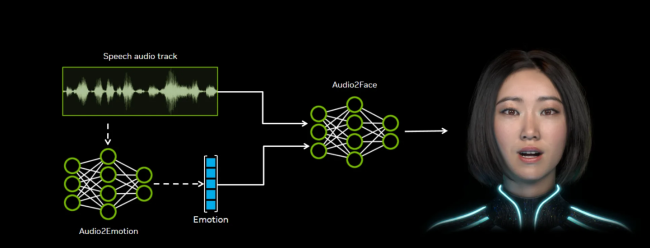
英伟达此次开源了多个核心组件,包括Audio2Face SDK、适用于Autodesk Maya的2.0版本本地执行插件、Unreal Engine 5.5及以上版本的2.5插件、回归模型和扩散模型。开源训练框架还支持开发者使用自有数据微调模型,以适应特定应用场景。

该技术已获行业广泛采用。例如,游戏开发商Survios在《异形:侠盗入侵进化版》中集成了Audio2Face,简化了口型同步与面部捕捉流程。Farm 51工作室也在《切尔诺贝利人2:禁区》中使用该技术,通过音频直接生成细腻面部动画,节省大量制作时间,提升角色真实感和沉浸体验。创新总监Wojciech Pazdur称此为“革命性突破”。
热点推送
-

《疯狂动物城 2》获 2026 元旦档票房冠军,即将超越《复仇者联盟 4》登顶进口片冠军榜
2026年元旦档(1月1日至1月3日)票房达到7.36亿,《疯狂动物城2》以2.19亿的档期票房成为冠军,并即将超越《复仇者联盟4:终局之战》,登顶中国影史进口片冠军榜
2026-01-04疯狂动物城,2,复仇者联盟 -
人形机器人登台唱戏:学习人类表演,精准复现戏曲身段
1月3日,2025《中国科技创新盛典》在CCTV-1频道播出。今年的节目在安徽合肥录制,特别策划了科技与戏剧结合的创演秀,创新演绎《徽班进京百戏入皖》
2026-01-04人形机器人 -
厂商 punkt. 推出“隐私手机”MC03,699 欧元 + 一年后每月 10 欧元订阅
近期,多家厂商推出了主打“隐私保护”的手机产品。punk.公司也宣布推出一款名为MC03的“隐私手机”。这款手机采用联发科天玑7300处理器和8GB RAM,定价为699欧元(约合5735元人民币),包含一年订阅服务
2026-01-04punkt.,MC03,AphyOS -
飞利浦 27 英寸显示器“27M2N5500XD”首销:720P 1000Hz/2K 540Hz 双模,4999 元
飞利浦旗下型号为“27M2N5500XD”的27英寸显示器将于明天0点在京东开启首销,定价为4999元。这款显示器主打2K 540Hz/720P 1000Hz
2026-01-04飞利浦,华星,HFS -
雷军:小米汽车 2026 年全年交付目标 55 万辆
小米创办人、董事长兼CEO雷军在新年直播中展示了工程师拆解一辆新的小米YU7的过程。直播期间,雷军宣布小米汽车2026年的全年交付目标为55万辆。 雷军还透露,小米汽车计划在2025年实现超过41万辆的交付量
2026-01-04小米汽车,小米交付,雷军 -
全国首单“具身智能数据集”在江苏省数据交易所上架并完成交易,为机器人注入“肌肉记忆”
近日,全国首单“具身智能数据集”在江苏省数据交易所上架并完成交易。这一数据集由江苏箸境智能科技有限公司提供,主要包含具身机器人所需的基础动作体感数据信息,包括视频、关节角度与力矩参数
2026-01-03江苏箸境智能科技有限公司,江苏省数据交易所,具身智能数据集 -
Instagram 负责人莫塞里谈 AI:现如今“眼见已不一定为实”
在2025年年末,Instagram负责人亚当·莫塞里通过一系列图片内容表达了他对“无限合成内容”时代的看法。随着合成影像技术的进步,现实与虚构的界限变得模糊
2026-01-03instagram,人工智能 -
特斯拉 2025 年第四季度交付量 418227 辆,全年近 164 万辆
特斯拉通过X平台公布了2025年第四季度的最新交付数据。该季度,特斯拉产量为434358辆,交付量为418227辆,储能部署达到14.2GWh
2026-01-03特斯拉 -
威刚将在 CES 2026 展示 64GB DDR5-7200 CUDIMM / CSODIMM 内存条
威刚 ADATA 宣布将参加 CES 2026,并在新闻稿中详细介绍了其参展阵容
2026-01-03威刚,CES2026 -
消息称苹果 A20 芯片单颗成本高达 280 美元,2nm 先进制程芯片恐成“史上最贵”
台积电和三星等芯片巨头正在推进2nm制程技术。台积电已经获得了苹果、高通和联发科的订单,而三星则计划利用2nm制程打造Exynos 2600芯片,用于Galaxy S26系列手机
2026-01-03苹果,A20,芯片 -
流媒体战略博弈:Netflix 收购华纳兄弟后拟将影院上映期缩短至 17 天,好莱坞担忧加剧
流媒体巨头Netflix计划在完成对华纳兄弟的收购后,将华纳兄弟电影的院线独占放映期缩短至17天。这一做法引发了传统影院及好莱坞电影创作者的担忧
2026-01-03Netflix,华纳兄弟 -
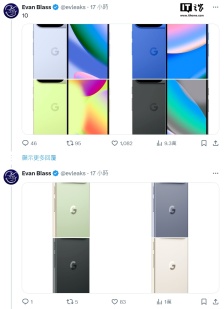
标准版、超大杯均有“撞色”设计,谷歌 Pixel 10 系列直板手机官图曝光
8月12日,消息人士Evan Blass在X平台曝光了谷歌Pixel 10系列直板手机的官方渲染图。 Pixel 10标准版提供黑曜石、靛蓝、霜白和柠檬酒四种颜色
2026-01-03谷歌,Pixel,10 -
马斯克:特斯拉 Robotaxi 服务下个月向公众开放
特斯拉首席执行官埃隆·马斯克近日确认,特斯拉的Robotaxi服务即将向公众开放,并给出了大致的时间表。该平台于6月22日在得克萨斯州奥斯汀首次向一小部分用户群体推出,在过去的一个半月里,公司不断扩大试乘用户数量和地理围栏范围
2026-01-03Robotaxi,特斯拉,马斯克 -
华硕公布 a 豆香氛机械键盘:65% 配列铝坨坨,右上角多媒体旋钮兼具香氛功能
华硕昨日正式公布了a豆香氛机械键盘 (adol KD202)。作为法国娇兰联名系列的一员,该键盘在右上角的多媒体旋钮中增添了香氛匣功能,可放入三种不同香调的香芯
2026-01-03华硕,键盘 -
3 分钟可成片,B站测试 AI 视频创作工具“花生 AI”
B站正在测试全新的AI视频创作工具“花生AI”,该工具主要以视频内容创作为主,目前仍处于测试阶段。使用“花生AI”时,用户只需准备好文案或录好的口播音频,就能快速生成成片,具体有两种方式可供选择。生成的视频可以直接发布到B站上
2026-01-03B站,AI,花生 -
鬼吹灯首部动画:《鬼吹灯之南海归墟》8 月 23 日开播,《凡人修仙传》制作团队打造
8月12日,《凡人修仙传》动画的制作团队万维猫动画发布预告,宣布《鬼吹灯之南海归墟》动画将于8月23日在腾讯视频开播。这部动画改编自天下霸唱的原著小说,讲述了胡八一、Shirley杨和王胖子三人组踏上寻找失落的青铜文明之旅的故事
2026-01-03鬼吹灯,凡人修仙传,国产动画 -
小鹏充电自营站突破 3000 站,超充站超 2650 座
小鹏汽车宣布,12月25日,浙江杭州千岛湖淳安县点亮了当地第一座也是全国第3000座自营充电站。到2025年最后一天,小鹏在全国上线的场站已超过3150座
2026-01-03小鹏汽车,小鹏充电 -
华硕:2026 年暂无推出新款智能手机的计划
华硕今日向媒体确认,2026年暂无推出新款智能手机的计划,但手机事业单位的营运维持不变。华硕表示,其手机产品的营运、产品维护、升级和保固都会持续进行。对于所有华硕手机用户,公司将持续提供完整的售后服务,保修条款与软件更新均不受影响
2026-01-03华硕,Zenfone,ROG -
技嘉预热新款 AORUS 系列英伟达 GeForce 显卡,搭载次世代散热
技嘉AORUS官方社媒账户发布了一条动态短视频,预热了即将在CES上公布的AORUS系列英伟达GeForce显卡新品。该型号采用了新一代的热力与气流工程技术,提升了稳定性,树立了GPU性能的新标准
2026-01-03技嘉,显卡,CES2026 -
Amazfit 跃我推出 Active Max 运动智能手表:1.5 英寸 3000nits 峰值亮度 OLED 圆屏
华米科技旗下的自主品牌Amazfit跃我在2025年末推出了Amazfit Active Max智能手表,这款手表专为日常运动爱好者和追求健康生活品质的人群设计
2026-01-03Amazfit -
从全平台选品地图到AI自动聊单,一文读懂出海匠2.0 Pro新功能
在跨境出海进入“全量AI化”的2026年,卖家面临的竞争早已不再是简单的商品价格战,而是运营效率的维度打击。
2026-01-02AI -
比亚迪方程豹 2025 年全年销量超 23.4 万辆,同比暴增 316.1%
比亚迪方程豹汽车公布了2025年的年度销售数据:全年共售出234637辆,同比增长316.1%。同年12月单月销量达到50868辆,环比增长36%,同比增幅为345.5%
2026-01-02比亚迪,方程豹 -
三星 Galaxy S26 系列手机“隐私显示”功能曝光,可阻止他人从侧面偷窥屏幕
科技媒体SamMobile近日发布消息称,三星Galaxy S26系列手机将引入一项名为“隐私显示”的新功能。这项功能旨在防止他人从侧面窥视屏幕内容
2026-01-02One,UI,8.5 -
ACEMAGIC 阿迈奇推出 Retro X5 迷你主机:NES 复古外观,锐龙 AI9 HX 370 处理器
ACEMAGIC阿迈奇在海外市场推出了Retro X5迷你主机,该款主机配备AMD锐龙AI 9 HX 370处理器,外观设计灵感来源于20世纪80年代的任天堂经典主机NES
2026-01-02AMD,锐龙,AI -
2025 年 12 月汽车销量 / 交付榜出炉:比亚迪依旧登顶、鸿蒙智行接近 9 万、小米首破 5 万
2025年国内汽车市场竞争激烈,新年伊始,各大厂商公布了年度数据。比亚迪继续保持销冠地位,新势力品牌也有亮眼表现。 比亚迪汽车销量为420398辆,具体数据未公布
2026-01-02比亚迪,新能源汽车,吉利汽车 -
消息称 OpenAI 大力研发音频 AI 模型,加紧备战首款“无屏幕”硬件设备
OpenAI 正在全面强化自身的音频人工智能能力,计划推出一款以语音为核心的个人AI设备。知情人士透露,这款设备将以听觉交互为主要形式,而非依赖屏幕。 目前,ChatGPT的语音功能与文本回答背后所使用的模型并不相同
2026-01-02OpenAI,奥尔特曼,音频AI -
华擎上线 PG-PSF 系列白金 SFX 电源:标准长度,耐受 235% 峰值负载
华擎 ASRock 官网现已上线幻影电竞 (Phantom Gaming) PG-PSF 系列白金 SFX 电源,提供 850W 和 1000W 两个功率版本
2026-01-02电源,华擎,SFX电源 -
百度:计划分拆昆仑芯业务并于港交所独立上市
百度集团宣布,昆仑芯已于1月1日通过其联席保荐人向香港证券交易所提交了上市申请表。预计在分拆完成后,昆仑芯仍将作为子公司存在。 昆仑芯是百度内部孵化的AI芯片公司,前身为百度智能芯片及架构部,专注于通用AI芯片的设计与生产
2026-01-02昆仑芯,百度,港交所 -
华为鸿蒙智家蓝牙网关 Lite 发布:兼容 2.4G/5G Wi-Fi、蓝牙 Mesh,129 元
华为推出了鸿蒙智家蓝牙网关 Lite,这款产品主打即插即用和简约设计,适用于兼容蓝牙和蓝牙 Mesh 协议的智能家居设备。它已经在华为商城上架,售价为129元
2026-01-02鸿蒙智家蓝牙网关,Lite,华为 -
为什么你的下一部手机必须具备端侧 AI?Arm 高管回应
在接受科技媒体采访时,Arm边缘AI业务执行副总裁Chris Bergey提到,尽管云端AI发展迅速,但端侧本地AI因低延迟、隐私保护及成本优势,仍然是未来计算的核心
2026-01-02安卓,手机,游戏