苹果联合中国人民大学发布 VSSFlow 模型:无声视频 AI 同步生成音效与配音
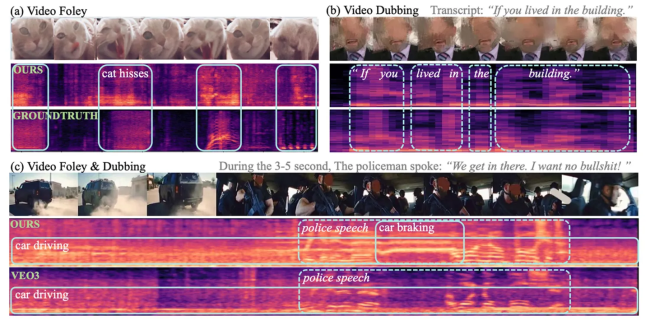
苹果公司与中国人民大学合作推出了一种名为VSSFlow的新型AI模型。该模型能够从无声视频中同时生成逼真的环境音效和人类语音,突破了传统音频生成技术的局限。VSSFlow的核心优势在于它能够在单一系统框架下直接处理无声视频数据,并同步生成与画面高度匹配的声音。
在VSSFlow出现之前,行业内的音频生成模型往往存在功能单一的问题。例如,视频转声音模型难以生成清晰的语音,而文本转语音模型又无法有效处理复杂的环境噪音。传统方法通常需要分阶段训练这两种模型,这不仅增加了系统的复杂性,还可能导致性能下降。VSSFlow采用10层架构设计并引入“流匹配”技术,使模型能够自主学习如何从随机噪声中重构出目标声音信号。
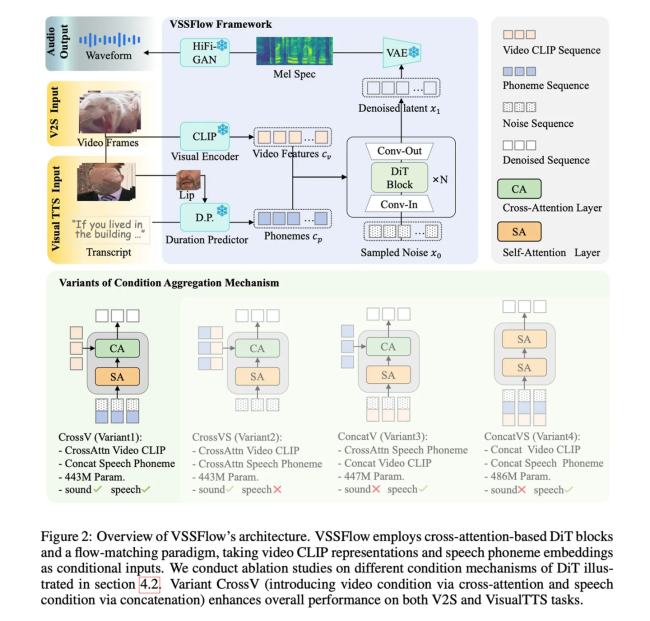
研究团队发现,在联合训练过程中,语音数据的训练提升了音效生成的质量,而音效数据的加入也优化了语音的表现。为了实现这一效果,团队向模型提供了混合数据集,包括配有环境音的视频、配有字幕的说话视频以及纯文本转语音数据,并通过合成样本对模型进行了微调,使其能够同时输出背景音与人声。

实际运行时,VSSFlow以每秒10帧的频率从视频中提取视觉线索来塑造环境音效,同时依据文本脚本精确引导语音生成。测试结果显示,该模型在多项关键指标上均优于专门针对单一任务设计的竞品模型。目前,研究团队已在GitHub上开源了VSSFlow的代码,并正在推进模型权重公开及在线推理演示的开发工作。
热点推送
-

OpenAI 升级 Codex、Sora 计费系统,避免触发限制“强制拉闸”
OpenAI 昨天宣布为Codex和Sora引入全新计费引擎,允许用户在达到速率限制时使用信用点数继续访问产品,避免传统计费系统因达到限制而突然中断服务的情况。新系统从底层重构,将速率限制、实时使用跟踪和信用点数余额整合进同一模型
2026-02-15OpenAI,Sora,Codex -
巴西反垄断机构调查微软,指其逼迫 OEM 厂独家捆绑 Edge 浏览器
巴西反垄断监管机构 CADE 最近开始调查微软,指控其间接逼迫部分 OEM 厂商独家捆绑 Edge 浏览器
2026-02-15Edge,浏览器,微软 -
广汽冯兴亚:过去一年汽车行业深度调整,作为承载近 10 万员工生计大型国有企业深知变革是唯一出路
广汽集团董事长冯兴亚近日发布长文,回顾了公司过去一年的变化、成就及未来规划。他表示,汽车行业正经历深度调整,广汽面临产业转型、技术迭代、管理重构和竞争格局变化的挑战
2026-02-15广汽集团,冯兴亚 -
华硕主板再现 R7 9800X3D 故障案例:未经手动超频,低负载过夜后发现电脑死机
近期,AMD R7 9800X3D 再次出现异常损坏案例,这次发生在华硕 TUF Gaming X870-Plus 主板上。据报道,故障发生时 CPU 负载不到 10%
2026-02-15华硕主板,AMD,R7 -
谢霆锋手持荣耀 Magic V6 被拍:大圆镜组、红色外观,新机有望今年 3 月发布
博主@旺仔百事通分享了一张照片,显示谢霆锋手持一款荣耀Magic V6的红色折叠屏手机。从图片中可以看到,这款手机延续了家族化设计语言,采用大圆镜组方案,边框和镜头模组用金色点缀,但具体颜色还需以真机上市为准
2026-02-15荣耀,Magic,V6 -
诺基亚宣布领导层调整,并成立技术与 AI 及企业发展两大新机构
诺基亚宣布了多项领导层调整,并计划成立两大全新机构——技术与人工智能机构以及企业发展机构,以强化公司的技术创新能力,为业务发展提供更有力的支持,并打造定位更精准的组织架构。这两大新机构将于2025年10月1日正式投入运作
2026-02-15诺基亚 -
索尼悄悄为欧版 Xperia 1 VII 手机推 Android 16 稳定版更新,用户发现界面变化不大
9月17日,索尼为欧版Xperia 1 VII手机推送了Android 16稳定版更新。更新包版本号为71.1.A.2.68,大小为1.13GB,适用于型号为XQ-FS54 EU的欧版Xperia 1 VII手机
2026-02-15Xperia,1,VII -
让 AI 真正“能做研究”,阿里通义 DeepResearch 模型、框架、方案全开源
阿里通义实验室宣布,为了使AI真正具备“做研究”的能力,对通义DeepResearch的数据、Agent范式、训练、基础设施和Test Time Scaling进行了系统性创新,并已将所有技术方案开源
2026-02-15阿里,通义,deepresearch -
Stellantis CEO 安东尼奥・菲洛萨确认,零跑明年起将在西班牙生产汽车
零跑已重启在欧洲建车的计划,并即将推出两款更适合欧洲市场的新车型。Stellantis 拥有零跑国际业务的大部分权利。Stellantis CEO 安东尼奥・菲洛萨表示,从 2026 年起,零跑将在西班牙生产汽车
2026-02-15Stellantis,零跑 -
长城进军高功率静音无风扇电源,钛金效率 ZERO 750W 以 1099 元上市
低噪声一直是高规格消费级电源的关键追求之一,而取消风扇回归被动散热是最彻底的解决方案。然而,高功率无风扇电源的设计和制造相对复杂,市场上仅有少数几家厂商涉足这一领域
2026-02-15长城电源,电源 -
宏碁 2 月 20 日起在日调价电脑产品,内存、固态硬盘涨价潮成主因
宏碁日本昨天在X平台发布公告,宣布官方在线商店将从2月20日起对电脑产品进行价格调整。此次调价主要是由于内存、固态硬盘等零部件价格上涨所致。现行价格将维持到2月19日,但部分产品的价格将保持不变。 宏碁并未公布具体涨幅
2026-02-15宏碁,固态硬盘,电脑 -
键盘可当触控板,Unihertz Titan 2 Elite 全键盘手机下月 MWC 2026 发布
Unihertz 在近一个月前宣布了 Titan 2 Elite,当时只透露了少量信息。今天,公司进一步宣布,这款手机将在 2026 年巴塞罗那 MWC 上正式发布
2026-02-15Unihertz,全键盘手机,MWC -
曝日本成人用品制造商 Tenga(典雅)被黑客入侵数据库,客户姓名、电子邮件等遭泄露
科技媒体TechCrunch报道,日本成人用品制造商Tenga发生了一起数据库泄露事件。根据获取的邮件内容,Tenga已向客户发出通知,说明有未经授权的第三方获得了员工工作邮箱的访问权限
2026-02-15Tenga,数据库泄露 -
摩尔线程完成 MiniMax M2.5 模型 Day-0 适配,支持 MTT S5000 GPU
摩尔线程今日完成了MiniMax M2.5模型的极速适配,成功在MTT S5000 AI推训一体全功能GPU上实现了高性能推理。MTT S5000 GPU采用MUSA架构,具备强大的算子覆盖与生态兼容性,能够释放原生FP8加速能力
2026-02-15摩尔线程,MTT,S5000 -
启境刘嘉铭谈新车进度:正和华为乾崑团队打磨产品,近百工程师要在极寒地区坚守 3-4 月测极限工况
启境汽车CEO刘嘉铭在2月13日发布视频,与华为智能汽车解决方案BU CEO靳玉志一起向用户拜早年,并透露新车开发进度
2026-02-15启境汽车,华为乾崑,刘嘉铭 -
EnGenius 推出 BE3600 无线 AP(接入点)ECW515,面板式设计
恩硕科技于本月12日在美国加州宣布推出面向酒店、多户住宅等领域的面板式Wi-Fi 7无线AP设备ECW515。这款设备具有双频BE3600的无线规格,在2.4GHz和5GHz频段均支持2T2R,信号覆盖范围可达约92.9平方米
2026-02-14无线AP,EnGenius -
24.5" 小尺寸 400Hz 高刷,优派推出 QHD 显示器 VX25G26-2K-4
ViewSonic 优派推出了一款型号为 VX25G26-2K-4 的显示器
2026-02-14优派,显示器 -
交通运输部:全国已有 396 家平台公司取得网约车平台经营许可,上月共收到订单信息 9.74 亿单
截至2026年1月31日,全国共有396家网约车平台公司取得网约车平台经营许可,较上月增加1家。网约车监管信息交互系统1月份共收到订单信息9.74亿单
2026-02-14交通运输部,网约车平台,网约车聚合平台 -
指尖“游历”四方:Pulsar 派世公布野外景观配色 CrazyLight 家族鼠标
韩国外设品牌Pulsar派世公布了CrazyLight系列鼠标的全新WildScapes主题配色型号。这一系列共有5款,分别是X2H“火山”、X3“沙漠”、X2N“海洋”、X2“森林”和Xlite“岩石”
2026-02-14Pulsar,鼠标 -
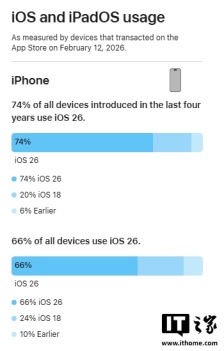
苹果 iOS 26 升级率与 iOS 18 接近,近四年 iPhone 安装比例为 74%
苹果公布了iOS 26与iPadOS 26系统的App Store数据,展示了目前有多少iPhone和iPad正在运行这两套系统版本。最新数据统计了截至2026年2月12日在App Store发生交易的iPhone与iPad设备
2026-02-14苹果,iPhone,iOS -
中国首部 AIGC 动画电影《团圆令》定档 2 月 28 日上映,以大熊猫为主题
中国首部AIGC动画电影《团圆令》定档2月28日,即将登陆全国院线。官方预告片已经发布。 该动画电影已于2025年12月20日在北京举行点映活动
2026-02-14AIGC,动画电影 -
地平线开源 HoloBrain VLA 基座模型,为机器人注入三维空间理解能力
2月13日,地平线宣布其HoloBrain-0基座模型及框架全面开源。此次开源不仅涵盖了HoloBrain-0的核心算法,还开放了完整的基础设施RoboOrchard。 从基础模型研究到可靠的机器人真机部署过程中存在巨大鸿沟
2026-02-14地平线,HoloBrain,机器人 -
英特尔发布最新 7028 版本驱动,支持《合金装备 Δ:食蛇者》《地狱即我们》
英特尔在本月22日推出了32.0.101.7026 WHQL版本显卡驱动程序,随后又发布了最新的7028驱动。新驱动主要是为《合金装备 Δ:食蛇者》和《地狱即我们》这两款游戏提供Game On支持
2026-02-14英特尔,显卡驱动,驱动程序 -
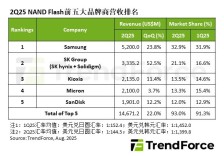
集邦:2025Q2 NAND 闪存五巨头相关营收环比增长 22%,平均单价小幅下滑
2025年第二季度,NAND闪存产业整体呈现价跌量升的态势。平均销售价格小幅下滑,但供需平衡的改善和中美市场政策推动按比特容量计的出货规模大幅增长
2026-02-14TrendForce,NAND,闪存 -
阿里夸克发布“教育计划”:AI 会员、网盘、扫描王面向教师、大学生限时免费提供
阿里旗下夸克近日宣布启动迄今为止最大规模的“教育计划”,面向全国近2000万教师和5000万高校学生,推出全面的AI“教育普惠”行动。该计划旨在降低AI工具的使用门槛
2026-02-14阿里,夸克,人工智能 -
小米澎湃 OS 3 桌面焕新,图标、状态栏、桌面网格重新设计
小米澎湃OS 3发布会正在进行中,除了公布“小米超级岛”外,还对锁屏和桌面进行了升级焕新。桌面图标、状态栏以及桌面网格都经过重新设计,官方表示这些改动使得图标更加高清细腻,状态栏更简洁精致,而桌面网格布局也变得更加均匀宽松
2026-02-14小米,澎湃OS3 -
消息称三星电子将以第二代 2nm 工艺 SF2P 代工特斯拉 AI6 处理器
三星电子计划使用第二代2nm工艺SF2P为特斯拉代工AI6处理器,并且这一制程节点还获得了DEEPX的DX-M2代工订单。据报道,三星电子将在韩国境内的先进制程和先进封装产线试产特斯拉AI6,随后在美国得克萨斯州泰勒市的新建晶圆厂实现量产
2026-02-14特斯拉,三星电子,先进制程 -
英特尔因盒装处理器保修规定违法在印被罚 27.38 亿卢比
印度反垄断监管机构印度竞争委员会 (CCI) 宣布对英特尔处以 27.38 亿卢比(约合 2.08 亿元人民币)的罚款,原因是该公司在 2016 年 4 月 25 日至 2024 年 4 月 1 日期间在印度市场执行了带有歧视性的保修政策
2026-02-14处理器,英特尔,印度 -
苹果 App Store 国区充值加赠 10% 活动开始:最高回赠 100 元,名额有限
苹果App Store国区上线了充值加赠优惠活动,只需充值5元以上即可获得10%的奖励,但名额有限,领完即止。根据活动页面显示,充值金额在5元至1000元之间均可享受优惠
2026-02-14App,Store,苹果 -
合并 xAI 后,消息称马斯克拟在 SpaceX IPO 前再融资以降低高息债务负担
2月13日晚间,据彭博社援引知情人士消息称,在SpaceX与xAI完成合并后,马斯克的银行顾问团队正在筹划新的融资方案,以降低过去几年积累的高额债务利息成本。马斯克因收购推特及创建人工智能公司,累计背负近180亿美元债务
2026-02-14马斯克,SpaceX,xAI