iPhone 上实现更快 AI 响应:苹果创新 MTP 技术,不牺牲质量模型输出速度最高提升 5 倍
苹果在最新研究中提出了一种名为“多 token 预测”(MTP)的技术,可以在不牺牲输出质量的情况下,将大语言模型的响应速度提升2到3倍,在某些特定场景下甚至可以达到5倍。传统的大语言模型采用自回归方式生成文本,逐个输出token,每一步都依赖前序内容,以保证连贯性。例如生成“The cat is black”时,模型需要在输出“is”后,基于上下文和训练经验从词汇表中计算“black”等候选词的概率,再选择最合适的词。这种串行机制虽然准确,但速度受限,特别是在移动设备上会影响用户体验。

苹果的新论文《Your LLM Knows the Future: Uncovering Its Multi-Token Prediction Potential》揭示了尽管模型仅被训练为预测下一个词,其内部其实蕴含对后续多个词的潜在判断能力。研究团队据此提出了“多 token 预测”框架,支持模型一次生成多个词。比如输入“The cat is
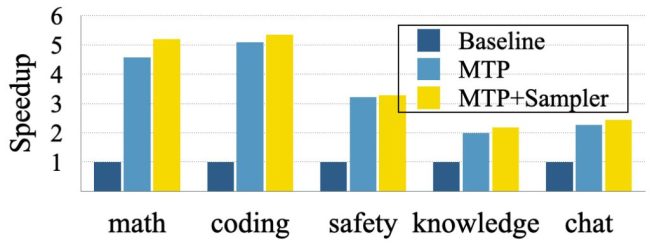
该技术的核心在于引入“掩码”(Mask)token作为占位符,并让模型并行推测后续多个词。每个推测结果会立即与标准自回归解码结果比对,若不符则自动回退到逐词生成模式,确保输出质量不受影响。“推测-验证”机制既提高了速度也保留了准确性。实验基于开源模型Tulu3-8B进行,结果显示,在问答和对话等通用任务中,响应速度平均提升2至3倍;在代码生成、数学推理等结构化场景中,提速可达5倍。
性能提升的关键在于采用了“门控LoRA适配”技术,动态调节参数,仅在必要时激活推测模块。这项研究为设备端大模型部署提供了新路径,相比依赖云端计算,MTP可以在iPhone、Mac等本地设备上实现更快响应,降低延迟与能耗。虽然目前仍处于研究阶段,但由于其兼容现有模型架构的特点,未来可能集成至Siri、Apple Intelligence等产品中,以提升用户交互体验。
热点推送
-
快手可灵 2.5 Turbo 模型上线,较上代模型便宜近 30%
快手的可灵AI基座模型再次升级,推出了可灵2.5 Turbo模型。新模型在文本理解和响应方面有了显著提升,能够更深入地理解复杂的因果关系指令,并实现对创意表达的精细化控制
2025-09-24快手,可灵 -

vivo OriginOS 6 更新有望全球首秀,海外取代 Funtouch OS
vivo开发者大会定于10月10日举行,届时将正式发布OriginOS 6更新。OriginOS 6有望迎来全球首秀,取代vivo手机在海外使用的Funtouch OS
2025-09-24OriginOS,6,vivo系统 -
15.98 万元起“最便宜鸿蒙智行”:尚界 H5 上市 1 小时大定突破 1 万台,9 月底陆续开始交付
尚界H5车型于9月23日正式上市,售价15.98万元起。搭载华为ADS 4高阶版的配置售价为17.98万元起。 上汽集团宣布,尚界H5上市一小时内大定订单突破1万台,计划于9月底陆续开始交付
2025-09-24尚界H5 -
热门笔记应用 Goodnotes 7.0.0 版本发布:白板、AI、焕新 UI,国内上一代老用户可直接升级
9月23日,热门笔记应用Goodnotes正式推出7.0.0版本。新版本不再称为Goodnotes 7,而是直接称为Goodnotes。以下是更新的主要内容: 新版本引入了两种文档类型:白板和文本文档
2025-09-24Goodnotes,笔记软件,笔记应用 -
雷柏 VT 二代鼠标全系迎 Power+ 固件升级,750h 续航、≤0.225ms 无线按键速度创新高
9月22日,雷柏宣布即将推送Power+固件技术(代号:炎龙),适用于VT二代无线电竞鼠标的所有型号,包括标准版和MAX版。升级后,这些鼠标将获得多项性能提升
2025-09-24雷柏鼠标,鼠标固件 -
我国移动互联网用户数突破 16 亿,8 月户均接入流量 20.87GB
9 月 23 日,工信部官网消息显示,前 8 个月通信业运行平稳。电信业务量和收入保持增长,新型基础设施建设有序推进,5G、千兆宽带、物联网等用户规模持续扩大,移动互联网接入流量增长较快
2025-09-23移动互联网,5G,工信部 -
iQOO 15 手机开启预约,号称“挑战电竞性能新巅峰”
iQOO 15 电竞性能技术沟通会将于9月23日14:30举行,宣称将“跨代领先”,挑战电竞性能新巅峰。目前,该机型已在京东开启预约,商品页面还显示同期将上新一款iQOO Pad5e平板电脑
2025-09-23iQOO,15,iQOO -
乔思伯 ITX 机箱 T9 开售:实木底座 + 铝制面板 + 可调中框,799 元
乔思伯旗下的T9机箱已在京东开售,这款A4 ITX产品采用左右分仓设计,显卡与主板背靠背安装,整体体积约为11.3L。中框可在三种不同的安装位置间调节,售价为799元
2025-09-23机箱 -
Meta:我们“很希望”能在雷朋眼镜上使用 iMessage,但苹果不允许
苹果的封闭生态策略不仅给监管机构和小型开发者带来挑战,也对科技巨头造成困扰
2025-09-23Meta,智能眼镜,苹果 -
小马智行与新加坡最大交通运营服务商康福德高合作,在当地部署自动驾驶出行服务
自动驾驶公司小马智行宣布进入新加坡市场,与当地最大交通运营服务商康福德高合作,部署自动驾驶车辆及相关服务。双方计划首先在新加坡榜鹅地区推出自动驾驶出行服务,该服务将在获得监管批准后正式启动
2025-09-23小马智行,自动驾驶 -
DeepSeek 线上模型升级至 V3.1-Terminus 版本,改进语言一致性及 Agent 能力
9月22日晚间,DeepSeek宣布其线上模型完成升级,版本号为DeepSeek-V3.1-Terminus。该版本包含思考模式和非思考模式两个版本,上下文长度均为128k,用户可以在线体验
2025-09-23DeepSeek -
系统比人还老几十岁:英国数十家银行仍在运行上世纪 60 年代的代码
英国不少银行至今仍在运行上世纪60、70年代的老旧代码,能够理解这些代码的员工寥寥无几。Baringa的一项调查显示,在接受调研的200家英国银行中,16%依赖于60年代的软件,近40%仍在维护70年代的代码
2025-09-23Cobol,软件,操作系统 -
迪士尼“星战”科幻电影《曼达洛人和格洛古》首曝中字预告,2026 年 5 月 22 日北美上映
迪士尼“星战”科幻电影《曼达洛人和格洛古》首支预告已发布,影片将于2026年全球献映,并于同年5月22日在北美上映
2025-09-23迪士尼,星战,曼达洛人和格洛古 -
东风汽车 & 华为联合创新实验室正式揭牌,重点围绕车载软件研发平台、辅助智能驾驶等方面加强合作
9月19日,在华为全联接大会2025的制造与大企业全球峰会汽车行业分论坛上,东风汽车与华为联合创新实验室正式揭牌。这是继今年5月23日双方签署战略合作协议后的又一个重要里程碑
2025-09-23东风汽车,联合创新实验室,华为 -
苹果 iOS 26 图乐园将添新引擎:接入更多模型,打造 AI 生图“聚合器”
9月23日,科技媒体9to5Mac发布消息称,在macOS Tahoe 26.1、iPadOS 26.1和iOS 26.1首个Beta开发者测试版中,苹果为图乐园(Image Playground)引入了新的框架支持
2025-09-23Siri,AI,图乐园 -
罗技推出灵砚系列 K868 三模机械键盘:有线 1KHz 回报率、晶石轴,399 元
罗技已在京东上架了灵砚系列 K868 三模客制化机械键盘,售价为 399 元。这款键盘提供有线 1KHz 回报率,并有黑白两种颜色可选
2025-09-23罗技,键盘 -
谷歌 DeepMind 更新前沿安全框架,应对模型“阻止自己被人类关闭”等风险
谷歌 DeepMind 更新了其核心 AI 安全文件“前沿安全框架”,新增了对“前沿模型可能阻止人类关闭或修改自己”这一风险的考量。一些新 AI 模型在测试中已展现出制定计划甚至使用欺骗手段达成目标的能力
2025-09-23谷歌,deepmind,人工智能 -
今日秋分:云清月秀,罗衫怯怯风露凉
今天是农历二十四节气中的秋分,这一天昼夜再次平分,阴阳相半,天气舒适宜人。秋分时阳光几乎直射赤道,之后北半球开始昼短夜长,冷空气逐渐活跃,需注意衣物增减。此时节,枫叶红似火,稻谷遍地黄,丹桂花飘香,蟹肥菊正黄,处处秋色迷人
2025-09-23二十四节气,秋分,秋天 -
又一欧洲车企选择放缓电动化,宾利确认未来仍将推出燃油新车
据外媒Autocar报道,宾利计划推出纯燃油版的添越、欧陆GT和飞驰继任车型。这标志着宾利“只有电动车”战略的逆转,其背后原因是保时捷上周的重大调整。根据Beyond100战略,宾利原计划到2035年全面淘汰燃油发动机
2025-09-23宾利,电动汽车 -
苹果 iOS/iPadOS 26.1 开发者预览版 Beta 发布
苹果于9月23日向iPhone和iPad用户推送了iOS/iPadOS 26.1开发者预览版Beta更新,内部版本号为23B5044l。这次更新距离上次发布Beta/RC版本间隔了16天
2025-09-23iOS,iPadOS -
智能床垫新国标公布,心率呼吸率测量误差需达标
市场监管总局(国家标准委)批准发布了《智能床垫》国家标准,该标准将于2026年3月1日正式实施。新标准为智能床垫产品的智能化、功能性及安全性设立了统一标尺
2025-09-22智能床垫 -
AOC 推出“AG326UZD”31.5 英寸显示器:4K 240Hz QD-OLED、DP 2.1 + 双扬,6499 元
AOC 已在京东上架了一款型号为 AG326UZD 的 31.5 英寸显示器,定价 6499 元。这款显示器主打 4K 240Hz QD-OLED 面板,配备双 8W 扬声器,支持原生 10-Bit 色彩和 DP2.1 接口
2025-09-22AOC,显示器 -
消息称 OPPO 首款轻智能手表即将发布,厚度不足 9mm 为目前最薄圆表
据博主@数码闲聊站透露,OPPO即将发布其首款轻智能手表,该手表厚度小于9毫米,可能是目前市面上最薄的圆形智能手表。新系统整体流畅度表现良好,接近手机操作系统水平,健康功能方面也有亮点
2025-09-22OPPO,智能手表 -
12.28 万元起,奇瑞 iCAR 全新超级 V23“方盒子”SUV 上市
奇瑞旗下iCAR全新超级V23“方盒子”SUV在发布会中正式上市,起售价为12.28万元。具体车型及价格如下:501巅峰性能版(V23 S)售价15.48万元;550超级运动版售价13.88万元;401超级运动版售价12.28万元
2025-09-22宁德时代,奇瑞,iCAR -
一加 15 真机曝光,设计风格延续一加 13T
一加 15 的真机照在 2025 和平精英职业联赛 PEL 夏季赛总决赛上亮相,并与历届和平精英冠军合影。从图片中可以看出,一加 15 背面采用左上角矩阵 Deco,设计风格延续了一加 13T,但不再与哈苏联名
2025-09-22一加15 -
华为汪涛:未来 5 年,计划每年投入 150 亿人民币生态发展费用、1500P 开源社区算力
在上周末的华为全联接大会2025上,华为常务董事汪涛发表主题演讲,强调了面向万物互联的智能时代,华为将坚持创新引领、开源开放,共创智能世界生态
2025-09-22汪涛,华为投入 -
LG 推出 48 英寸电竞电视 48G5 Ultra:4K 144Hz OLED、α11 芯片,首发价 7999 元
LG 推出了一款 48G5 Ultra 电竞电视,型号为 OLED48G5PCA。这款电视主打 4K 144Hz,定价为 8999 元,首发价 7999 元,在部分地区享受国补后到手价可降至 6399 元
2025-09-22LG,显示器,电视 -
小米精英驾驶赛道日明起开启报名:车主价 1499 元,非小米车主 1999 元
小米精英驾驶・赛道日将于9月22日上午10:00开启报名,小米车主尊享价为1499元,非小米车主价为1999元
2025-09-22小米汽车,SU7,Ultra -
ColorOS 16 发布会暨 OPPO 开发者大会定档 10 月 15 日,官网展示液态玻璃设计元素
OPPO 官网宣布,ColorOS 16 发布会暨 OPPO 开发者大会将于 2025 年 10 月 15 日在深圳举行
2025-09-22ColorOS,16,OPPO -
2025 年“科学探索奖”获奖名单公布:每人 300 万奖金,杨振宁、马化腾等发起
9月20日,第七届“科学探索奖”颁奖典礼在深圳举行,50位科学家获得该奖项。这项由腾讯出资、新基石科学基金会运营、多位知名科学家与腾讯创始人马化腾共同发起的公益奖项,是目前国内金额最高的青年科技人才资助项目之一
2025-09-22科学探索奖,杨振宁,马化腾