摩尔线程大模型对齐研究获国际顶级学术会议认可:URPO 框架入选 AAAI 2026
摩尔线程提出了一种新的大语言模型对齐框架——URPO统一奖励与策略优化。该研究论文已被人工智能领域的国际顶级学术会议AAAI 2026收录,为简化大模型训练流程和突破模型性能上限提供了全新的技术路径。
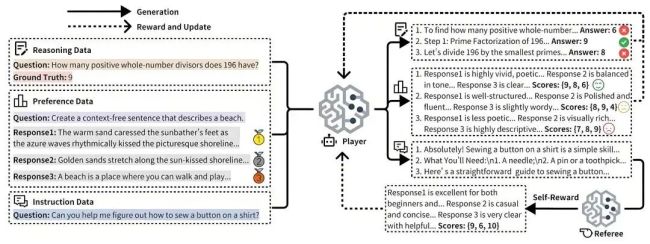
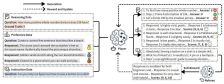
在题为《URPO: A Unified Reward & Policy Optimization Framework for Large Language Models》的论文中,摩尔线程AI研究团队提出了URPO统一奖励与策略优化框架,将“指令遵循”和“奖励评判”两大角色融合于单一模型中,并在统一训练阶段实现同步优化。URPO从三个方面攻克技术挑战:数据格式统一、自我奖励循环和协同进化机制。
数据格式统一方面,URPO将异构的偏好数据、可验证推理数据和开放式指令数据重构为适用于GRPO训练的信号格式。自我奖励循环方面,对于开放式指令,模型生成多个候选回答后,自主调用其“裁判”角色进行评分,并将结果作为GRPO训练的奖励信号,形成一个高效的自我改进循环。协同进化机制方面,通过在同一批次中混合处理三类数据,模型的生成能力与评判能力得以协同进化。生成能力提升带动评判更精准,而精准评判进一步引导生成质量跃升,从而突破静态奖励模型的性能瓶颈。
实验结果显示,基于Qwen2.5-7B模型,URPO框架超越依赖独立奖励模型的传统基线。在AlpacaEval指令跟随榜单上,得分从42.24提升至44.84;在综合推理能力测试中,平均分从32.66提升至35.66。此外,该模型内部自然涌现出的评判能力在RewardBench奖励模型评测中取得85.15的高分,表现优于其替代的专用奖励模型(83.55分)。
目前,URPO已在摩尔线程自研计算卡上实现稳定高效运行,并已完成VERL等主流强化学习框架的深度适配。
热点推送
-

小米发布 Miloco 智能家居未来探索方案,对全社会开放
小米发布了智能家居未来探索方案Miloco,该方案旨在通过大模型驱动全屋智能生活。用户可以通过与智能家居系统对话沟通,经过系统的推理计算后,自动完成家庭生活中的各类智能需求和规则,无需再为复杂的智能规则费心
2025-11-14小米,智能家居,米家 -
铭凡 X1 Lite-255 迷你主机发布:AMD Ryzen 7 255 处理器、0.84L 体积,1999 元起
铭凡 X1 Lite-255 迷你主机今日正式发布,体积约 0.84L,搭载 AMD Ryzen 7 255 处理器,支持直连独显,售价 1999 元起(准系统 / 无内存硬盘系统)
2025-11-14铭凡,AMD,Ryzen -
迪士尼 CEO 鲍勃・艾格:希望人们用 AI 为 Disney+ 创作精品内容
迪士尼CEO鲍勃・艾格对将AI技术应用于Disney+充满信心。在迪士尼第四财季电话会议上,艾格详细讨论了AI在增强公司直接面向消费者策略方面的潜力
2025-11-14迪士尼,人工智能 -
摩尔线程冲刺“国产 GPU 第一股”,11 月 24 日启动申购
11月13日晚间,摩尔线程披露科创板上市招股意向书,股票代码为“688795”,冲刺“国产GPU第一股”。本次拟发行数量7000万股,占发行后总股本的比例为14.89%
2025-11-14摩尔线程,GPU,科创板上市 -
迈凯伦首款 SUV 预计 2028 年问世:定位高端,比保时捷卡宴 Turbo GT 更大
迈凯伦首款高性能SUV预计将在2028年问世,目前该项目已进入成型阶段。经销商透露,这款新车将是一款混动SUV,其轮廓让人联想到保时捷卡宴Turbo GT,但更大、更具雕塑感与力量感,并配备24英寸轮毂
2025-11-14迈凯伦,迈凯伦SUV -
14999 元铭凡 MS-S1 MAX 迷你主机国行预售:锐龙 AI Max+ 395、128G RAM 配 2T SSD
铭凡基于AMD锐龙AI Max+ 395 "Strix Halo"处理器的AI工作站迷你主机解决方案MS-S1 MAX已在京东上架并开启定金预售
2025-11-14MS,S1,MAX -
高盛:人工智能热潮并非泡沫,才刚刚起步
尽管市场对人工智能泡沫的担忧日益加剧,但高盛认为这场AI繁荣才刚刚开始。这家华尔街巨头的分析师指出,当前的投资规模与AI所能带来的潜在经济回报相比仍然较小
2025-11-14AI,人工智能,高盛 -
华为商城上架鸿蒙智行享界 S9 汽车 1:18 合金车模:方向盘可联动车轮转向、后视镜可折叠,898 元
华为商城上架了鸿蒙智行享界 S9 汽车的 1:18 合金车模,提供寰宇红和浩宇蓝两种配色,售价均为 898 元。这款车模采用四门两盖全开合设计,前备箱、后备箱及四扇车门均可开启,并支持方向盘精准联动汽车车轮转向和后视镜折叠
2025-11-14鸿蒙智行享界,S9,享界 -
努比亚 Z80 Ultra 手机预热:自定义全能键、滤镜“调色盘”功能,10 月 22 日发布
努比亚Z80 Ultra新机将于10月22日14时正式发布,其Slogan为“能拍能打,绝世有双”,强调了十三年的影像技术积累。这款手机将配备自定义全能键,用户可以一键启动任意应用,并且支持滤镜“调色盘”功能,允许用户打造个性化的滤镜风格
2025-11-14努比亚,Z80,Ultra -
消息称苹果从微信小程序消费中抽取 15% 分成,腾讯回应
腾讯公司与苹果公司达成了一项协议,根据该协议,苹果将处理微信小游戏和应用中的支付事宜,并从中抽取15%的分成。在腾讯集团2025年第三季度财报电话会上,腾讯管理层回应称,腾讯与苹果有着良好的合作关系,在多个方面进行了合作
2025-11-14微信小程序,苹果,腾讯 -
摩尔线程大模型对齐研究获国际顶级学术会议认可:URPO 框架入选 AAAI 2026
摩尔线程提出了一种新的大语言模型对齐框架——URPO统一奖励与策略优化。该研究论文已被人工智能领域的国际顶级学术会议AAAI 2026收录,为简化大模型训练流程和突破模型性能上限提供了全新的技术路径
2025-11-14AAAI,2026,URPO -
比亚迪轿卡 T4 发布:62.3kWh 刀片电池、150kW 扁线电机输出 204 匹马力,首发价 9.58 万元起
比亚迪轿卡T4在武汉国际商用车车展上正式发布,最大容积可达15方,搭载62.3kWh刀片电池和150kW扁线电机,输出204匹马力,首发价9.58万元起
2025-11-14刀片电池,比亚迪轿卡,T4 -
小米“Ultra Club | 走进小米深圳总部”活动明日报名:探秘专业手机实验室、产品经理面对面交流等
小米汽车官方宣布,“Ultra Club | 走进小米深圳总部”活动将于11月14日17:00启动报名,共提供15个名额。活动定于11月22日15:00-18:00在深圳市的小米深圳大厦举行
2025-11-14小米深圳总部,小米,Ultra -
英特尔确认下一代 Nova Lake CPU 支持 AVX10.2、APX 指令集,覆盖桌面 / 移动端
英特尔在最新发布的《架构扩展指令编程参考》指南中确认,下一代Nova Lake架构CPU将支持AVX10.2和APX指令集。新文档指南在“未来英特尔芯片特定路线图”中列出了AVX 10.1和AVX 10.2指令集,涵盖消费者芯片
2025-11-14英特尔,Nova,Lake -
雷神 MIX NUC 迷你主机配置上新:AMD 锐龙 AI 9 HX 370,售价 6999 元
雷神推出了全新一代MIX NUC迷你主机,搭载AMD锐龙AI 9 HX 370移动处理器,提供32GB DDR5内存和1TB SSD存储,新品到手价为6999元,国补后价格为5599.2元
2025-11-13雷神,MIX,NUC -
小米之家重返法国巴黎,首家直营店即将开业
11月11日,小米法国副国家经理在微博上宣布,巴黎首家小米之家即将开业。这家新店将是直营门店。有网友询问之前在香榭丽舍大街是否已有店铺,对此,该经理回应称之前的店铺是由客户开设,因疫情原因暂时退出了市场
2025-11-13小米之家,巴黎 -
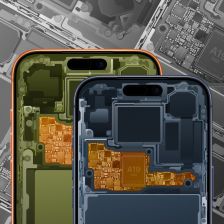
打磨近 3000 个图层:设计师推苹果 iPhone 17 Pro / Max 全新“透视”壁纸,9 种色调
设计师Basic Apple Guy耗时两个多月,为iPhone 17 Pro和iPhone 17 Pro Max创作了内部结构主题壁纸。这些壁纸之所以细节惊人,是因为其素材直接源于苹果官方的维修手册
2025-11-13iPhone,17,Pro -
法拉第未来宣布接入特斯拉超级充电网络,明年新车型配备 NACS 接口
法拉第未来 Faraday Future 宣布,自2026年起推出的新车型将配备NACS(北美充电标准)接口,并可直接接入特斯拉超级充电网络
2025-11-13法拉第未来,特斯拉充电,NACS -
奥迪全新概念赛车 R26 首秀,官宣明年进军 F1 赛事
明年新赛季揭幕时,奥迪将首次亮相F1赛场。为此,奥迪正式发布了全新的R26概念车,让外界提前一睹奥迪赛车的风采
2025-11-13奥迪,F1 -
美国法官推迟批准 Epic 与谷歌和解协议,需等待法律发生重大变化才能一锤定音
加州一名法官推迟批准Epic与谷歌之间的和解协议,这意味着两家公司关于内购抽成的纷争尚未结束。Epic在2020年起诉谷歌,指控其Android系统的Play商店构成事实性垄断,理由是超过95%的Android应用都通过Play商店分发
2025-11-13Epic,谷歌 -
自研 AI 芯片进展缓慢,微软 CEO 纳德拉计划借“OpenAI 之力”推进研发
北京时间今天清晨,据彭博社报道,微软计划借助对OpenAI定制AI芯片研发的访问权来推动自研芯片进展。微软CEO纳德拉在播客节目中表示,即使OpenAI在系统层面进行创新,微软也能全面获取这些成果
2025-11-13OpenAI,微软,纳德拉 -
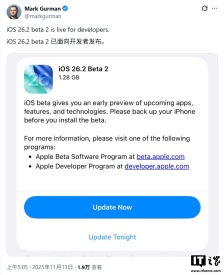
苹果 iOS 26.2 Beta 2 更新汇总:UI 动画更 Q 弹、拓展液体玻璃设计
科技媒体9to5Mac发布了一篇关于苹果iOS 26.2 Beta 2更新内容的文章。此次更新主要为“测距仪”和“水平仪”等原生应用整合了液态玻璃设计语言,并调整了部分系统动画,使其更具弹性
2025-11-13iOS,26,苹果 -
Steam Machine 游戏主机正式亮相:Steam Deck 掌机 6 倍性能、支持光追,明年初开售
今天凌晨,Valve 正式发布了全新的硬件产品——“主机级”设备 Steam Machine。该设备将率先在目前销售 Steam Deck 的地区同步上市,计划于 2026 年初开售,具体价格与时间待后续公布
2025-11-13Steam,Steam,Machine -
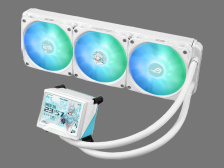
华硕 ROG STRIX 吹雪 360 LCD 方屏版水冷上市,1529 元
华硕在10月末于电商平台上架了一款AIO水冷新品——ROG STRIX吹雪360 LCD方屏版,售价为1529元
2025-11-13华硕,水冷散热器 -
苹果 iOS/iPadOS 26.2 开发者预览版 Beta 2 发布
苹果今日向iPhone和iPad用户推送了iOS/iPadOS 26.2开发者预览版Beta 2更新,内部版本号为23C5033g。此次更新距离上次发布Beta/RC版本间隔8天
2025-11-13iOS,iPadOS -
涉案超 27 亿元!跨境赌博“十大逃犯”之一、“亚太新城”赌诈犯罪集团主犯佘智江成功引渡回国
近日,据媒体报道,我国公安机关通缉的跨境赌博“十大逃犯”之一、缅甸妙瓦底“亚太新城”赌诈犯罪集团主犯佘智江被成功从泰国引渡回国。这是中泰执法司法合作取得的重大成果,彰显了双方坚决打击网赌电诈犯罪的决心
2025-11-13电信诈骗,网络赌博,跨境赌博 -
智能手机厂商首家:小米应用商店打通腾讯元器智能体分发,无需额外开发或适配
小米应用商店宣布与腾讯官方智能体平台——腾讯元器完成能力打通,成为首家接入该平台的智能手机厂商。腾讯元器是一个零代码智能体创建与分发平台,提供低门槛的创建能力和优秀模型支持
2025-11-13小米应用商店,腾讯元器 -
奇瑞汽车就“天门山测试意外”致歉:防护绳脱落致车辆撞击护栏,将全力修复并承担赔偿责任
奇瑞汽车在11月13日凌晨发布了一份关于天门山挑战测试意外情况的致歉声明。声明中提到,2025年11月12日中午12时,风云X3L车型在湖南张家界天门山景区进行极限挑战测试时发生意外,导致测试中断,引起广泛关注
2025-11-13奇瑞汽车,风云,X3L -
小米米家 App 安卓端推送 11.1.505.302 体验版,3D 家居视图上线
小米近期为安卓用户推送了米家App的11.1.505.302体验版本,更新中引入了一系列新功能。其中包括“场景”页面和全屋动态看板,并对设计风格进行了调整
2025-11-12米家,App,小米米家 -
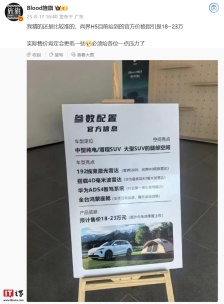
消息称鸿蒙智行尚界 H5 汽车官方价格指引 18~23 万元,实际可能更低
近日,博主@Blood旌旗分享了尚界H5的官方价格指引,该车定价在18至23万元之间。博主表示,实际售价可能会更低一些。 根据博主分享的图片,尚界H5定位为中型纯电/增程SUV,拥有大型SUV的腿部空间
2025-11-12尚界,H5,鸿蒙智行